
KT 믿음 2.0 사용법 : 오픈소스 다운로드 및 설치 방법 (Midm)
KT 믿음 2.0 사용법 : 오픈소스 다운로드 및 설치 방법 (Midm)
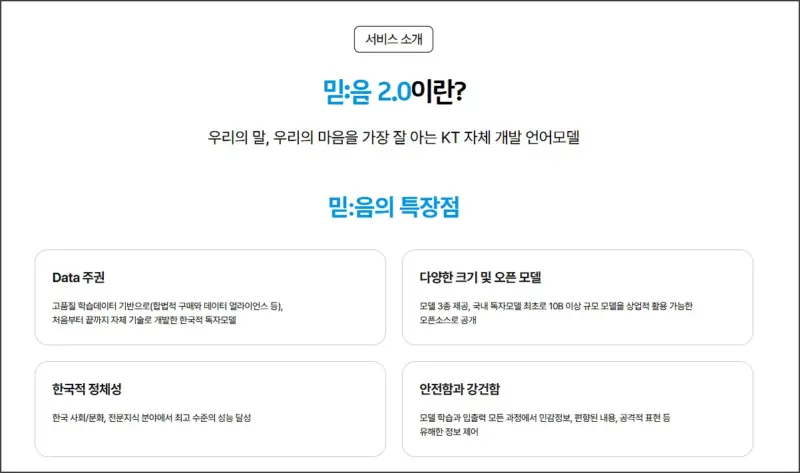
최근 KT에서 자체 개발한 한국형 AI 언어모델인 ‘믿:음 2.0’을 오픈소스로 공개했다는 소식이 화제가 되고 있는데요. 기존에 외국 기업들이 만든 AI 모델들과 달리, 처음부터 한국어와 한국 문화를 깊이 이해하도록 설계된 모델이라고 하니 상당히 관심이 가더라구요.
특히 무려 115억(11.5B) 파라미터 규모의 대형 모델을 누구나 상업적으로 활용할 수 있도록 공개한 것은 국내에서는 처음이라고 하는데요. 개발자나 AI에 관심이 있으신 분들이라면 한 번쯤 사용해보고 싶으실 것 같습니다.
그렇기에 이번 포스팅에서는 KT 믿음 2.0 사용법과 오픈소스 다운로드 방법에 대해서 알아보려고 합니다. 허깅페이스에서 직접 다운로드하는 방법부터 LM Studio를 활용한 간편한 사용법까지 함께 살펴보도록 하죠.
1. KT 믿음 2.0이란?
KT 믿음 2.0은 ‘한국적 AI’라는 철학을 담아 자체 개발한 언어모델(LLM)로, 처음부터 끝까지 KT의 자체 기술로 개발한 한국적 독자 모델입니다. 2023년에 1.0 버전을 출시한 이후로 KT AICC, 지니TV, AI 전화 등 다양한 서비스에 활용되어 왔다고 하네요.
이번에 공개된 2.0 버전은 총 3가지 모델로 구성되어 있는데요. Mini는 소형 디바이스에서도 작동될 수 있도록 설계된 모델로, 사용자 의도 이해, 번역 등 특정 기능에 특화되어 있습니다. Base는 모델의 크기와 성능 사이의 밸런스를 갖춘 범용 모델입니다.
현재 허깅페이스에 공개된 모델은 Mini(23억 파라미터)와 Base(115억 파라미터) 두 가지인데요. 개인적으로는 Base 모델이 한국어 이해와 생성 성능이 훨씬 뛰어나다고 느껴지더라구요.
무엇보다 기업과 개인, 공공 누구나 상업적으로 활용할 수 있도록 제약 없이 개방되어 있다는 점이 가장 큰 장점인 것 같습니다. MIT 라이선스로 공개되어 있어서 자유롭게 수정하고 배포할 수 있죠.
2. 허깅페이스에서 다운로드하기
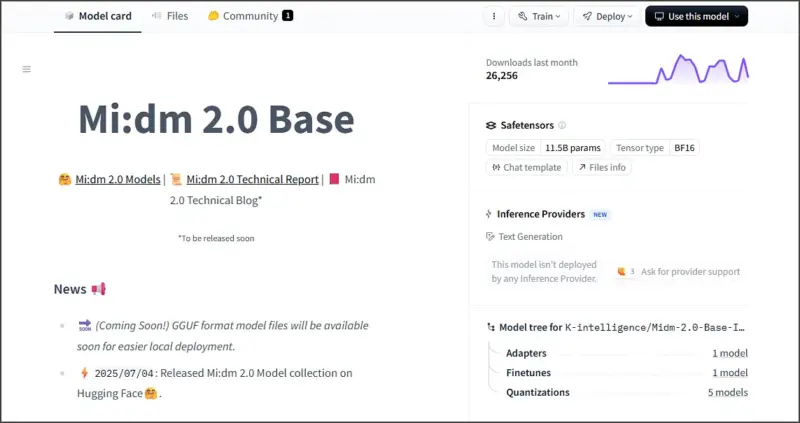
※ KT 믿음 2.0 huggingface 사이트 링크
KT 믿음 2.0을 사용하기 위해서는 우선 허깅페이스에서 모델을 다운로드해야 하는데요. 직접 코드로 사용하시려는 분들을 위한 방법부터 알아보도록 하겠습니다.
먼저 Python 환경에서 transformers 라이브러리가 설치되어 있어야 하는데요. 터미널이나 명령 프롬프트에서 아래 명령어를 입력해주시면 됩니다.
pip install transformers torch이후에는 다음과 같은 코드를 사용하여 모델을 로드하고 대화형 추론을 실행할 수 있습니다:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfig
model_name = "K-intelligence/Midm-2.0-Base-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
generation_config = GenerationConfig.from_pretrained(model_name)
prompt = "KT에 대해 소개해줘"
messages = [
{"role": "system", "content": "Mi:dm(믿:음)은 KT에서 개발한 AI 기반 어시스턴트이다."},
{"role": "user", "content": prompt}
]
input_ids = tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_tensors="pt"
)
output = model.generate(
input_ids.to("cuda"),
generation_config=generation_config,
max_new_tokens=128
)
print(tokenizer.decode(output[0]))다만 Base 모델의 경우 115억 파라미터라서 GPU 메모리가 충분해야 원활하게 동작하는데요. 최소 12GB 이상의 VRAM이 필요하다고 보시면 됩니다. 그렇기에 GPU메모리가 부족하신 분들은 Mini 모델을 사용하시거나 프렌들리 AI에서 이용해보시는 것을 권장드립니다.
3. LM Studio로 간편하게 사용하기
하지만 위의 방법이 다소 복잡하게 느껴지실 수 있는데요. 이런 경우에는 LM Studio를 활용하면 훨씬 간편하게 KT 믿음 2.0을 사용할 수 있습니다.
LM Studio를 사용하면 몇 번의 클릭만으로 Mi:dm 2.0을 쉽게 사용할 수 있습니다. 우선 LM Studio를 다운로드하고 설치해주셔야 하는데요. 공식 홈페이지에서 Windows, Mac, Linux 버전을 모두 지원하고 있습니다.
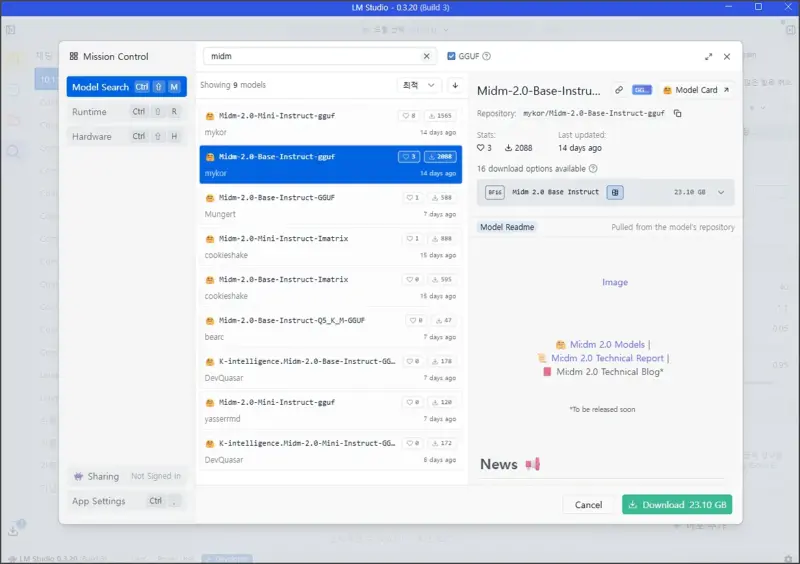
LM Studio를 실행하신 후에는 좌측의 탐색 아이콘을 누르고 Midm 2.0을 검색해주시면 되는데요. 검색 결과에서 원하는 모델을 선택하고 다운로드 버튼을 클릭하면 자동으로 다운로드가 진행됩니다.
개인적으로는 GGUF 형식의 모델을 추천드리는데요. 일반적인 모델보다 용량이 작고 로딩 속도도 빠른 편이라서 개인 PC에서 사용하기에 적합합니다.
다운로드가 완료되면 Chat 탭으로 이동해서 바로 대화를 시작할 수 있는데요. 한국어로 질문하면 상당히 자연스러운 한국어로 답변을 해주는 것을 확인할 수 있습니다.
실제로 사용해보니 다른 오픈소스 모델들에 비해서 한국 문화나 역사, 사회적 맥락을 훨씬 잘 이해하는 것 같더라구요. 특히 한국어 특유의 뉘앙스나 존댓말 사용도 자연스러운 편이었습니다.
이 외에도 터미널에서 llama.cpp를 사용하여 직접 실행하는 방법도 있는데요. huggingface-cli를 사용하여 GGUF 형식의 모델을 다운로드한 후, llama-cli 명령어로 실행할 수 있습니다:
huggingface-cli download K-intelligence/Midm-2.0-Base-Instruct-GGUF \
--include "Midm-2.0-Base-Instruct-GGUF-BF16.gguf" \
--local-dir .
llama-cli \
-m ./Midm-2.0-Base-Instruct-GGUF-BF16.gguf \
-p "KT에 대해 소개해줘" \
--temp 0.7이렇게 하면 GUI 없이도 터미널에서 바로 모델을 사용할 수 있어서, 서버 환경이나 자동화된 작업에 활용하기 좋습니다.
4. 맺음말
오늘은 KT 믿음 2.0 사용법과 오픈소스 다운로드 방법에 대해서 알아보았습니다.
한국 기업이 자체 개발한 언어모델을 이렇게 누구나 사용할 수 있도록 공개한다는 것은 정말 의미있는 일이라고 생각되는데요. 특히 한국어와 한국 문화를 깊이 이해하는 AI 모델이 필요했던 개발자들에게는 좋은 선택지가 될 것 같습니다.
다만 아직은 GPT-4나 Claude 같은 최신 모델들에 비해서는 성능이 부족한 것도 사실인데요. 하지만 ‘호랑이 리더보드3’에서 파라미터 수 150억개 미만 국내 기업 개발 모델 가운데 종합 성능 1위를 기록했다고 하니, 앞으로의 발전이 더욱 기대되네요.
개인적으로는 한국어 특화 작업이나 온디바이스 AI 개발에 활용하면 좋을 것 같고, 특히 Mini 모델은 가벼워서 모바일 앱이나 엣지 디바이스에서도 충분히 활용 가능할 것 같습니다. 앞으로 더 많은 한국형 AI 모델들이 공개되어서 국내 AI 생태계가 활성화되기를 기대해봅니다.